Design and architechture¶
The package design can be found in the figure below.
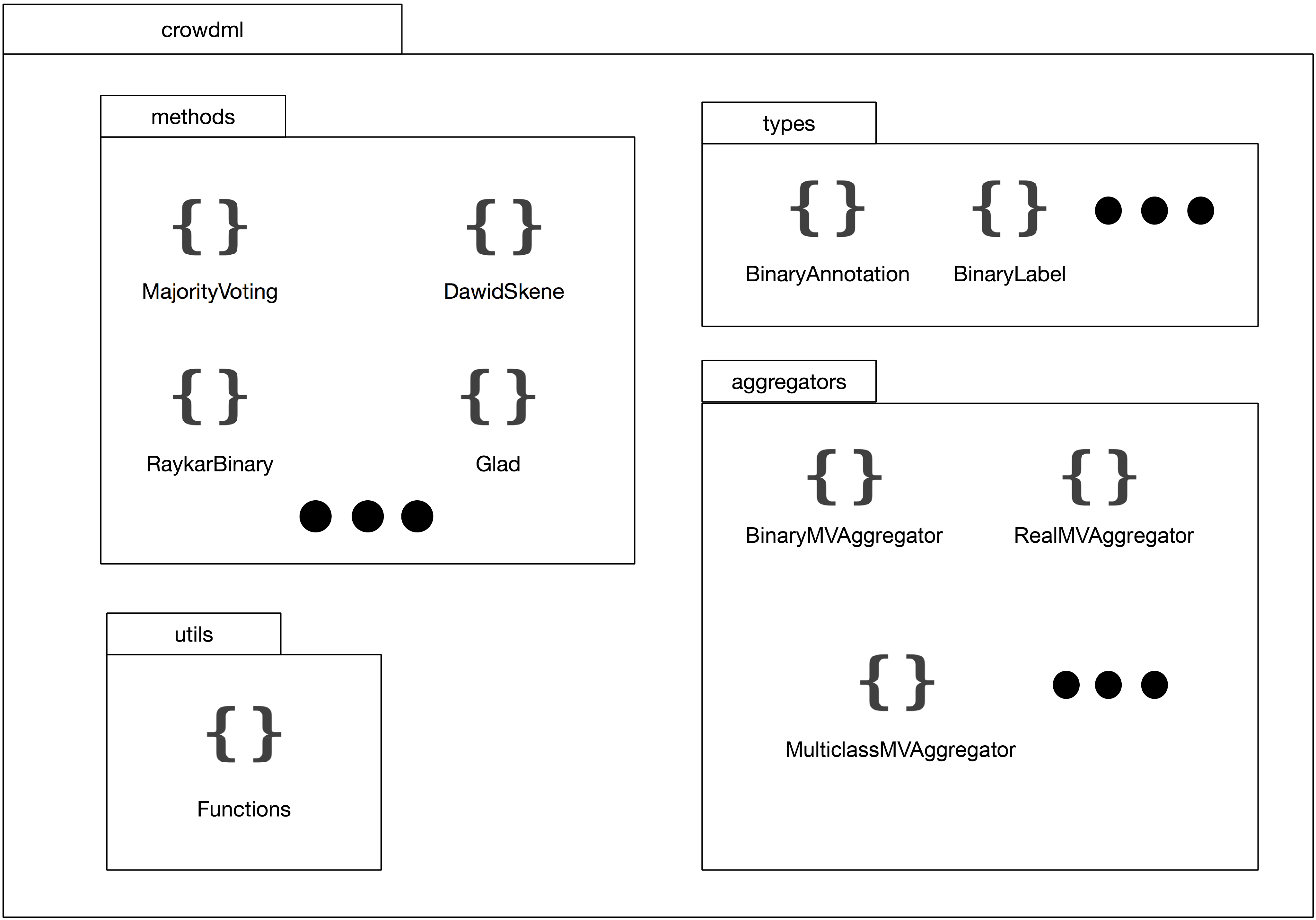
Although, the library contains several folders, the only importart folders for the users
are the types folder, and the methods folder. The other folders contain auxiliary
functions some of the methods. Specifically, in interesting to explore the data types, as
they are essential to understand how the package works, as well as the common interface of
the methods.
Data types¶
The package provides types for annotations datasets and ground truth datasets, as they usually follow the same structure. These types are used in all the methods so you would need to convert your annotations dataset to the correct format accepted by the algorithm.
There are three types of annotations that the package supports for which we provide Scala case classes, making it possible to detect errors at compile time when using the algorithms:
BinaryAnnotation: a Dataset of this type provides three columns: * Theexamplecolumn (i.e the example for which the annotation is made). * Theannotatorcolumn (representing the annotator that made the annotation). * Thevaluecolumn, (with the value of the annotation, that can take as value either 0 or 1)MulticlassAnnotation: The difference formBinaryAnnotationis that thevaluecolumn can take more than two values, in the range from 0 to the total number of values.RealAnnotation: In this case, thevaluecolumn can take any numeric value.
You can convert an annotation dataframe with columns example, annotator and value to a
typed dataset easily with the following instruction:
val typedData = untypedData.as[RealAnnotation]
In the case of labels, we provide 5 types of labels, 2 of which are probabilistic. The three non probabilistic types are:
BinaryLabel. A dataset with two columns:exampleandvalue. The column value is a binary number (0 or 1).MulticlassLabel. A dataset with the same structure as the previous one but where the columnvalueis a binary number (0 or 1).RealLabel. In this case, the columnvaluecan take any numeric value.
The probabilistic types are used by some algorithms, to provide more information about the confidence of each class value for an specific example.
BinarySoftLabel. A dataset with two columns:exampleandprob. The columnprobrepresents the probability of the example being positive.MultiSoftLabel. A dataset with three columns:example,classandprob. This last column represents the probability of the example taking the class in the columnclass.
Methods¶
All methods implemented are in the methods subpackage and are mostly independent of each other. There MajorityVoting algorithms are the
only exception, as most of the other methods use them in the initialization step. Apart from that, each algorithm is implemented in its
specific file. Apart from that, each algorithm
is implemented in its specific file. This makes it easier to extend the package with new algorithms. Although independent, all algorithms have
a similar interface, which facilitates its use. To execute an algorithm, the user normally needs to use the apply method of the model (which
in scala, is equivalent to applying the object itself), as shown below
...
val model = IBCC(annotations)
...
After the model completes its execution, a model object is returned, which will have information about the ground truth estimations and other estimations that are dependent on the chosen algorithm.
The only algorithm that does not follow this pattern is MajorityVoting, which has methods for each of the class types and also to obtain
probabilistic labels. See the API Docs for details.